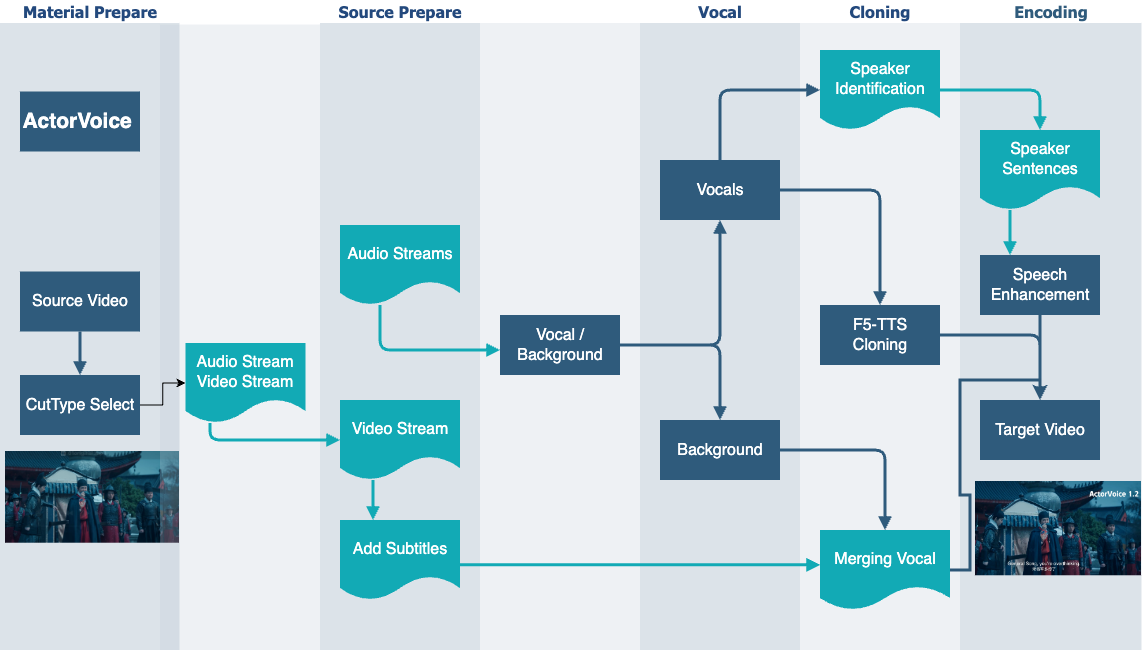
Cross-lingual video dubbing presents significant challenges in maintaining speaker identity, emotional
expressiveness, and natural speech flow while translating content across languages. Traditional approaches
often result in synthetic-sounding voice, inconsistent prosody, and loss of original speaker
characteristics, limiting the widespread adoption of automated dubbing solutions.
This paper introduces ActorVoice, a novel zero-shot cross-lingual dubbing framework that achieves
professional-quality voice translation through several key innovations. First, we propose an advanced
F5-based text-to-speech synthesis system enhanced with dynamic utterance merging, which effectively
preserves natural speech patterns and emotional nuances across language boundaries. Second, we develop a
high-precision voice-background separation module that achieves superior audio track isolation while
maintaining environmental acoustics. Third, our intelligent audio fusion system implements adaptive
prosody matching and coherent style transfer, effectively addressing common issues such as robotic
artifacts, tonal inconsistencies, and unnatural transitions.
Our framework incorporates three key technical contributions: (1) a context-aware utterance analysis
mechanism that optimizes speech segment boundaries for natural flow, (2) a neural prosody transfer network
that accurately captures and reproduces speaker-specific characteristics, and (3) an adaptive audio mixing
pipeline that ensures seamless integration of synthesized speech with background elements. Extensive
experiments demonstrate that ActorVoice achieves comparable quality to professional human dubbing services
and outperforms existing solutions like Heygen across multiple evaluation metrics.
Quantitative evaluations on our multi-language dubbing benchmark show that ActorVoice achieves a Mean
Opinion Score (MOS) of 4.6 for naturalness and 82% for speaker similarity, representing a significant
improvement over current state-of-the-art systems. User studies indicate that 96% of participants could
not distinguish our synthesized dubbing from professional human recordings. These results demonstrate the
potential of ActorVoice to revolutionize cross-lingual video content adaptation while maintaining high
production quality.