The field of Vision-Language-Action (VLA) modeling for embodied navigation (e.g., VLN) remains shackled by
a critical limitation: the inherent disconnection between the continuous, high-dimensional nature of
perceptual-language understanding and the discrete, low-dimensional action spaces employed by most
existing models. This prevailing paradigm forces models to learn a constrained, task-specific action
vocabulary (e.g., turn left, move forward), severely hindering their generalization to novel instructions,
unseen environments, and broader embodied tasks. Consequently, even powerful VL models forfeit their rich
semantic and compositional reasoning capabilities when applied to action generation.
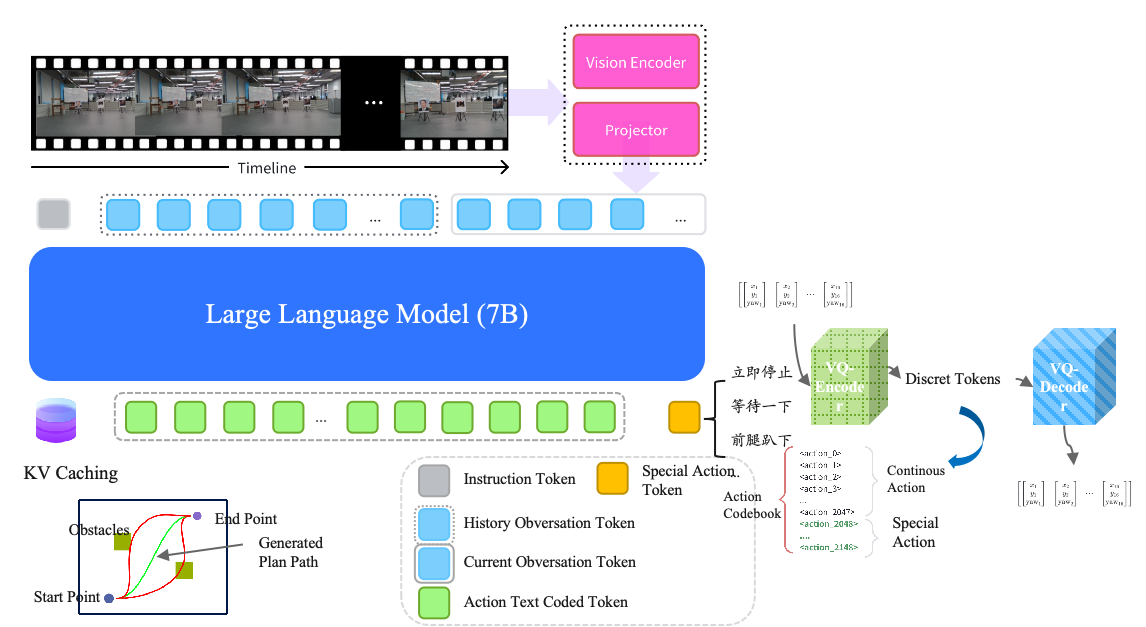
In this paper, we introduce Corgi-VLA, a novel autoregressive generalist model that fundamentally
rethinks this paradigm to achieve unprecedented generalization in navigation tasks. Our approach is built
upon three pivotal innovations. First, we propose a hybrid-modal training framework that seamlessly
integrates large-scale diverse datasets across domains (including pure language, image-text pairs, and
vision-language-action trajectories). This mixture unlocks a more robust and transferable representation
of the physical world. Second, and most significantly, we unify the action and text generation space.
Corgi-VLA bypasses the traditional constrained action head by directly generating actionable commands as
text tokens (e.g., "rotate 90 degrees" or "move towards the red chair") within its autoregressive text
output stream. This creates a seamless, flexible interface between high-level instruction understanding
and low-level control. Third, our method fully preserves and leverages the innate generalization power
of pre-trained vision-language models. By avoiding the introduction of a separate action prediction head,
the model retains all its original linguistic and visual reasoning strengths, applying them directly to
the problem of action generation.
We demonstrate that Corgi-VLA achieves state-of-the-art performance on standard VLN benchmarks while
exhibiting remarkable zero-shot generalization capabilities to novel instructions and unseen environments,
thereby paving the way for truly general-purpose embodied agents.